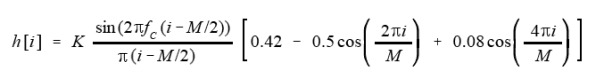Over the past couple of years, I’ve built up a nice library of DSP code, including effects, oscillators, and utilities. One thing that always bothered me however, is how to test this code in an efficient and reliable way. The two main methods I have used in the past have their pros and cons, but ultimately didn’t satisfy me.
One is to process an effect or generate a source into a wave file that I can open with an audio editor so I can listen to the result and examine the output. This method is okay, but it is tedious and doesn’t allow for real-time adjustment of parameters or any sort of instant feedback.
For effects like filters, I can also generate a text file containing the frequency/phase response data that I can view in a plotting application. This is useful in some ways, but this is audio — I want to hear it!
Lately I’ve gotten to know Pure Data a little more, so I thought about using it for interactive testing of my DSP modules. On its own, Pure Data does not interact with code of course, but that’s where libpd comes in. This is a great library that wraps up much of Pure Data’s functionality so that you can use it right from your own code (it works with C, C++, Objective-C, Java, and others). Here is how I integrated it with my own code to set up a nice flexible testing framework; and this is just one application of using libpd and Pure Data together — the possiblities go far beyond this!
First we start with the Pure Data patches. The receiver patch is opened and maintained in code by libpd, and has two responsiblities: 1) generate a test tone that the effect is applied to, and 2) receive messages from the control patch and dispatch them to C++.

Receiver patch, opened by libpd.
The control patch is opened in Pure Data and acts as the interactive patch. It has controls for setting the frequency and volume of the synthesizer tone that acts as the source, as well as controls for the filter effect that is being tested.

Control patch, opened in Pure Data, and serves as the interactive UI for testing.
As can be seen from the patches above, they communicate to each other via the netsend/netreceive objects by opening a port on the local machine. Since I’m only sending simple data to the receiver patch, I opted to use UDP over TCP as the network protocol. (Disclaimer: my knowledge of network programming is akin to asking “what is a for loop”).
Hopefully the purpose of these two patches is clear, so we can now move on to seeing how libpd brings it all together in code. It is worth noting that libpd does not output audio to the hardware, it only processes the data. Pure Data, for example, commonly uses Portaudio to send the audio data to the sound card, but I will be using Core Audio instead. Additionally, I’m using the C++ wrapper from libpd.
An instance of PdBase is first created with the desired intput/output channels and sample rate, and a struct contains data that will need to be held on to that will become clear further on.
struct TestData
{
AudioUnit outputUnit;
EffectProc effectProc;
PdBase* pd;
Patch pdPatch;
float* pdBuffer;
int pdTicks;
int pdSamplesPerBlock;
CFRingBuffer<float> ringBuffer;
int maxFramesPerSlice;
int framesInReserve;
};
int main(int argc, const char * argv[])
{
PdBase pd;
pd.init(0, 2, 48000); // No input needed for tests.
TestData testData;
testData.pd = &pd;
testData.pdPatch = pd.openPatch("receiver.pd", ".");
}
Next, we ask Core Audio for an output Audio Unit that we can use to send audio data to the sound card.
int main(int argc, const char * argv[])
{
PdBase pd;
pd.init(0, 2, 48000); // No input needed for tests.
TestData testData;
testData.pd = &pd;
testData.pdPatch = pd.openPatch("receiver.pd", ".");
{
AudioComponentDescription outputcd = {0};
outputcd.componentType = kAudioUnitType_Output;
outputcd.componentSubType = kAudioUnitSubType_DefaultOutput;
outputcd.componentManufacturer = kAudioUnitManufacturer_Apple;
AudioComponent comp = AudioComponentFindNext(NULL, &outputcd);
if (comp == NULL)
{
std::cerr << "Failed to find matching Audio Unit.\n";
exit(EXIT_FAILURE);
}
OSStatus error;
error = AudioComponentInstanceNew(comp, &testData.outputUnit);
if (error != noErr)
{
std::cerr << "Failed to open component for Audio Unit.\n";
exit(EXIT_FAILURE);
}
Float64 sampleRate = 48000;
UInt32 dataSize = sizeof(sampleRate);
error = AudioUnitSetProperty(audioUnit,
kAudioUnitProperty_SampleRate,
kAudioUnitScope_Input,
0, &sampleRate, dataSize);
AudioUnitInitialize(audioUnit);
}
}
The next part needs some explanation, because we need to consider how the Pure Data patch interacts with Core Audio’s render callback function that we will provide. This function will be called continuously on a high priority thread with a certain number of frames that we need to fill with audio data. Pure Data, by default, processes 64 samples per channel per block. It’s unlikely that these two numbers (the number of frames that Core Audio wants and the number of frames processed by Pure Data) will always agree. For example, in my initial tests, Core Audio specified its maximum block size to be 512 frames, but it actually asked for 470 & 471 (alternating) when it ran. Rather than trying to force the two to match block sizes, I use a ring buffer as a medium between the two — that is, read sample data from the opened Pure Data patch into the ring buffer, and then read from the ring buffer into the buffers provided by Core Audio.
Fortunately, Core Audio can be queried for the maximum number of frames it will ask for, so this will determine the number of samples we read from the Pure Data patch. We can read a multiple of Pure Data’s 64-sample block by specifying a value for “ticks” in libpd, and this value will just be equal to the maximum frames from Core Audio divided by Pure Data’s block size. The actual number of samples read/processed will of course be multiplied by the number of channels (2 in this case for stereo).
The final point on this is to handle the case where the actual number of frames processed in a block is less than the maximum. Obviously it would only take a few blocks for the ring buffer’s write pointer to catch up with the read pointer and cause horrible audio artifacts. To account for this, I make the ring buffer twice as long as the number of samples required per block to give it some breathing room, and also keep track of the number of frames in reserve currently in the ring buffer at the end of each block. When this number exceeds the number of frames being processed in a block, no processing from the patch occurs, giving the ring buffer a chance to empty out its backlog of frames.
int main(int argc, const char * argv[])
{
<snip> // As above.
UInt32 framesPerSlice;
UInt32 dataSize = sizeof(framesPerSlice);
AudioUnitGetProperty(testData.outputUnit,
kAudioUnitProperty_MaximumFramesPerSlice,
kAudioUnitScope_Global,
0, &framesPerSlice, &dataSize);
testData.pdTicks = framesPerSlice / pd.blockSize();
testData.pdSamplesPerBlock = (pd.blockSize() * 2) * testData.pdTicks; // 2 channels for stereo output.
testData.maxFramesPerSlice = framesPerSlice;
AURenderCallbackStruct renderCallback;
renderCallback.inputProc = AudioRenderProc;
renderCallback.inputProcRefCon = &testData;
AudioUnitSetProperty(testData.outputUnit,
kAudioUnitProperty_SetRenderCallback,
kAudioUnitScope_Input,
0, &renderCallback, sizeof(renderCallback));
testData.pdBuffer = new float[testData.pdSamplesPerBlock];
testData.ringBuffer.resize(testData.pdSamplesPerBlock * 2); // Twice as long as needed in order to give it some buffer room.
testData.effectProc = EffectProcess;
}
With the output Audio Unit and Core Audio now set up, let’s look at the render callback function. It reads the audio data from the Pure Data patch if needed into the ring buffer, which in turn fills the buffer list provided by Core Audio. The buffer list is then passed on to the callback that processes the effect being tested.
OSStatus AudioRenderProc (void *inRefCon,
AudioUnitRenderActionFlags *ioActionFlags,
const AudioTimeStamp *inTimeStamp,
UInt32 inBusNumber,
UInt32 inNumberFrames,
AudioBufferList *ioData)
{
TestData *testData = (TestData *)inRefCon;
// Don't require input, but libpd requires valid array.
float inBuffer[0];
// Only read from Pd patch if the sample excess is less than the number of frames being processed.
// This effectively empties the ring buffer when it has enough samples for the current block, preventing the
// write pointer from catching up to the read pointer.
if (testData->framesInReserve < inNumberFrames)
{
testData->pd->processFloat(testData->pdTicks, inBuffer, testData->pdBuffer);
for (int i = 0; i < testData->pdSamplesPerBlock; ++i)
{
testData->ringBuffer.write(testData->pdBuffer[i]);
}
testData->framesInReserve += (testData->maxFramesPerSlice - inNumberFrames);
}
else
{
testData->framesInReserve -= inNumberFrames;
}
// NOTE: Audio data from Pd patch is interleaved, whereas Core Audio buffers are non-interleaved.
for (UInt32 frame = 0; frame < inNumberFrames; ++frame)
{
Float32 *data = (Float32 *)ioData->mBuffers[0].mData;
data[frame] = testData->ringBuffer.read();
data = (Float32 *)ioData->mBuffers[1].mData;
data[frame] = testData->ringBuffer.read();
}
if (testData->effectCallback != nullptr)
{
testData->effectCallback(ioData, inNumberFrames);
}
return noErr;
}
Finally, let’s see the callback function that processes the filter. It’s about as simple as it gets — it just processes the filter effect being tested on the audio signal that came from Pure Data.
void EffectProcess(AudioBufferList* audioData, UInt32 numberOfFrames)
{
for (UInt32 frame = 0; frame < numberOfFrames; ++frame)
{
Float32 *data = (Float32 *)audioData->mBuffers[0].mData;
data[frame] = filter.left.sample(data[frame]);
data = (Float32 *)audioData->mBuffers[1].mData;
data[frame] = filter.right.sample(data[frame]);
}
}
Not quite done yet, though, since we need to subscribe the open libpd instance of Pure Data to the messages we want to receive from the control patch. The messages received will then be dispatched inside the C++ code to handle appropriate behavior.
int main(int argc, const char * argv[])
{
<snip> // As above.
pd.subscribe("fromPd_filterfreq");
pd.subscribe("fromPd_filtergain");
pd.subscribe("fromPd_filterbw");
pd.subscribe("fromPd_filtertype");
pd.subscribe("fromPd_quit");
// Start audio processing.
pd.computeAudio(true);
AudioOutputUnitStart(testData.outputUnit);
bool running = true;
while (running)
{
while (pd.numMessages() > 0)
{
Message msg = pd.nextMessage();
switch (msg.type)
{
case pd::PRINT:
std::cout << "PRINT: " << msg.symbol << "\n";
break;
case pd::BANG:
std::cout << "BANG: " << msg.dest << "\n";
if (msg.dest == "fromPd_quit")
{
running = false;
}
break;
case pd::FLOAT:
std::cout << "FLOAT: " << msg.num << "\n";
if (msg.dest == "fromPd_filterfreq")
{
filter.left.setFrequency(msg.num);
filter.right.setFrequency(msg.num);
}
else if (msg.dest == "fromPd_filtertype")
{
// (filterType is just an array containing the available filter types.)
filter.left.setState(filterType[(unsigned int)msg.num]);
filter.right.setState(filterType[(unsigned int)msg.num]);
}
else if (msg.dest == "fromPd_filtergain")
{
filter.left.setGain(msg.num);
filter.right.setGain(msg.num);
}
else if (msg.dest == "fromPd_filterbw")
{
filter.left.setBandwidth(msg.num);
filter.right.setBandwidth(msg.num);
}
break;
default:
std::cout << "Unknown Pd message.\n";
std::cout << "Type: " << msg.type << ", " << msg.dest << "\n";
break;
}
}
}
}
Once the test has ended by banging the stop_test button on the control patch, cleanup is as follows:
int main(int argc, const char * argv[])
{
<snip> // As above.
pd.unsubscribeAll();
pd.computeAudio(false);
pd.closePatch(testData.pdPatch);
AudioOutputUnitStop(testData.outputUnit);
AudioUnitUninitialize(testData.outputUnit);
AudioComponentInstanceDispose(testData.outputUnit);
delete[] testData.pdBuffer;
return 0;
}
The raw synth tone in the receiver patch used as the test signal is actually built with the PolyBLEP oscillator I made and discussed in a previous post. So it’s also possible (and very easy) to compile custom Pure Data externals into libpd, and that’s pretty awesome! Here is a demonstration of what I’ve been talking about — testing a state-variable filter on a raw synth tone: