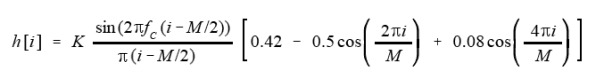This post has been edited to clarify some of the details of implementing the polyphase resampler [May 14, 2013].
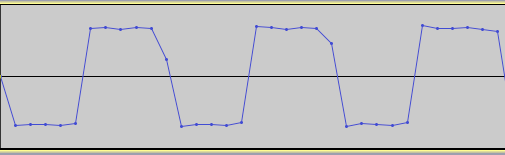
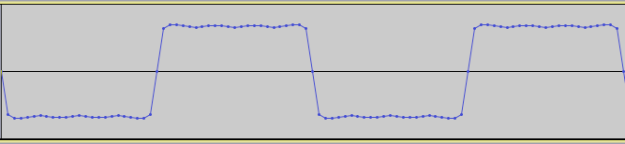
Time to finish up this look at resampling. In Part 1 we introduced the need for resampling to avoid aliasing in signals, and its implementation by windowed sinc FIR filters. This is a costly operation, however, especially for real-time processing. Let’s consider the case of upsampling-downsampling a 1 second audio signal at a sampling rate of 44.1 kHz and a resampling factor of 4X. Going about this with the brute-force method that we saw in Part 1 would result in first upsampling the signal by 4X. This results in a buffer size that has now grown to be 4 x 44100 = 176,400 that we now have to filter, which will obviously take roughly 4 times as long to compute. And not only once, but twice, because the decimation filter also operates at this sample rate. The way around this is to use polyphase interpolating filters.
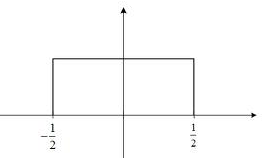
A polyphase filter is a set of subfilters where the filter kernel has been split up into a matrix with each row representing a subfilter. The input samples are passed into each subfilter that are then summed together to produce the output. For example, given the impulse response of the filter

we can separate it into two subfilters, E0 and E1
![]()
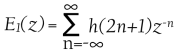
where E0 contains the even-numbered kernel coefficients and E1 contains the odd ones. We can then express H(z) as
![]()
This can of course be extended for any number of subfilters. In fact, the number of subfilters in the polyphase interpolating/decimating filters is exactly the same as the resampling factor. So if we’re upsampling-downsampling by a factor of 4X, we use 4 subfilters. However, we still have the problem of filtering on 4 times the number of samples as a result of the upsampling. Here is where the Noble Identity comes in. It states that for multirate signal processing, filtering before upsampling and filtering after downsampling is equivalent to filtering after upsampling and before downsampling.

Noble Identities for upsampling and downsampling.
When you think about it, it makes sense. Recall that upsampling involves zero-insertion between the existing samples. These 0 values, when passed through the filter, simply evaluate out to 0 and have no effect on the resulting signal, so they are wasted calculations. We are now able to save a lot of computational expense by filtering prior to upsampling the signal, and then filtering after downsampling. In other words, the actual filtering takes place at the original sample rate. The way this works in with the polyphase filter is quite clever: through a commutator switch.
Let’s take the case of decimation first because it’s the easier one to understand. Before the signal’s samples enter the polyphase filter, a commutator selects every Mth sample (M is the decimation factor) to pass into the filter while discarding the rest. The results of each subfilter is summed together to produce the signal, back to its original sample rate and without aliasing components. This is illustrated in the following diagram:

Polyphase decimator with a commutator switch that selects the input.
Interpolation works much the same, but obviously on the other end of the filter. Each input sample from the signal passes through the polyphase filter, but instead of summing together the subfilers, a commutator switch selects the outputs of the subfilters that make up the resulting upsampled signal. Think of it this way: one sample passes into each of the subfilters that then results in L outputs (L being the interpolation factor and the number of subfilters). The following diagram shows this:

Polyphase interpolating filter with a commutator switch that selects the output.
We now have a much more efficient resampling filter. There are other methods that exist as well to implement a resampling filter, including Fast Fourier Transform, which is a fast and efficient way of doing convolution, and would be a preferred method of implementing FIR filters. At lower orders however, straight convolution is just as fast (if not even slightly faster at orders less than 60 or so) than FFT; the huge gain in efficiency really only occurs with a kernel length greater than 80 – 100 or so.
Before concluding, let’s look at some C++ code fragments that implement these two polyphase structures. Previously I had done all the work inside a single method that contained all the for loops to implement the convolution. Since we’re dealing with a polyphase structure, it naturally follows that the code should be refactored into smaller chunks since each filter branch can be throught of as an individual filter.
First, given the prototype filter’s kernel, we break it up into the subfilter branches. The number of subfilters (branches) we need is simply equal to the resampling factor. Each filter branch will then have a length equal to the prototype filter’s kernel length divided by the factor, then +1 to take care of rounding error. i.e.
branch order = (prototype filter kernel length / factor) + 1
The total order of the polyphase structure will then be equal to the branch order x number of branches, which will be larger than the prototype kernel, but any extra elements should be initialized to 0 so they won’t affect the outcome.
The delay line, z, for the interpolator will have a length equal to the branch order. Again, each branch can be thought of as a separate filter. First, here is the decimating resampling code:

Example of decimating resampler code.
As can be seen, calculating each polyphase branch is handled by a separate object with its own method of calculating the subfilter (processDownsample). We index the input signal with variable M, advances at the rate of the resampling factor. The gain adjust can be more or less ignored depending on how the resampling is implemented. In my case, I have precalculated the prototype filter kernels to greatly improve efficiency. However, the interpolation process decreases the level of the signal by an amount equal to the resampling factor in decibels. In other words, if our factor is 3X, we need to amplify the interpolated signal by 3dB. I’ve done this by amplifying the prototype filter kernel so I don’t need to adjust the gain during interpolation. But this means I need to compensate for that in decimation by reducing the level of the signal by the same amount.
Here is the interpolator code:

Example of interpolation resampler code.
As we can see, it’s quite similar to the decimation code, except that the output selector requires an additional for loop to distribute the results of the polyphase branches. Similarly though, it uses the same polyphase filter object to calculate each filter branch, using the delay line as input instead of the input signal directly. Here is the code for the polyphase branches:

Code implementing the polyphase branches.
Again, quite similar, but with a few important differences. The decimation/downsampling MACs the input sample by each kernel value whereas interpolation/upsampling MACs the delay line with the branch kernel.
Hopefully this clears up a bit of confusion regarding the implementation of the polyphase filter. Though this method splits up and divides the tasks of calculating the resampling into various smaller objects than before, it is much easier to understand and maintain.
Resampling, as we have seen, is not a cheap operation, especially if a strong filter is required. However, noticeable aliasing will render any audio unusable, and once it’s in the signal it cannot be removed. Probably the best way to avoid aliasing is to prevent it in the first place by using band-limited oscillators or other methods to keep all frequencies below the Nyquist limit, but this isn’t always possible as I pointed out in Part 1 with ring modulation, distortion effects, etc. There is really no shortage of challenges to deal with in digital audio!